



Hadoop Network Engineering
Big Data/Hadoop Network Engineering
Hadoop and other distributed systems are increasingly the solution of choice for next-generation “Big Data” volumes. A high-capacity, easily manageable networking layer is critical for peak Hadoop performance. Data analytics has become a key element of the business decision process over the last decade. The ability to process unprecedented volumes of data is a crucial competitive aspect and essential deliverable service in the information economy. Classic systems based on relational databases and expensive hardware, while still useful for some applications, are increasingly unattractive compared to the scalability, economics, processing power and availability offered by today’s network-driven distributed solutions. Perhaps the most popular of these next- generation systems is Hadoop, a software framework that drives the compute engines in data centers from IBM to Facebook.
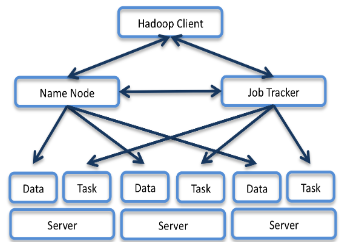
Hadoop and the related Hadoop Distributed File System (HDFS) form an open source framework that allows clusters of commodity hardware servers to run parallelized, data-intensive workloads. Given sufficient storage, processing and networking resources, the possibilities are nearly endless. The HDFS stores/replicates multiple copies of data in 64MB chunks throughout the system for fault tolerance and improved availability. Because replication is accomplished node-to-node rather than top down, a well-architected Hadoop cluster needs to be able to handle significant any-to-any traffic loads.
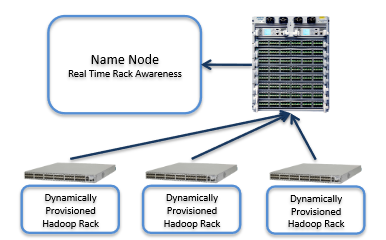
Hadoop is unique in that it has a “rack aware” file system – it actually understands the relationship between which servers are in which cabinet and which switch supports them. With this information it is able to better distribute data and ensure that a copy of each set of data is distributed across different servers connected to different switches. This is a data loss prevention function that prevents any single switch failure from causing data loss.
Hadoop is also a Layer 3 aware file system – it uses IP for node addressing. This means it is routable. There is no requirement, nor benefit to building a large and flat Layer-2 network for Hadoop. It allows you to use routing, building a scalable, stable and easily supported ECMP network based on OSPF in the smaller deployments and BGP in the larger ones, and it will be stable and contain broadcasts and faults to each cabinet.
Operationally these are simpler networks to troubleshoot and maintain with full toolsets available in every host stack and network element: Traceroute, Ping, Arping, fping, etc., are available for L3 network day-to-day troubleshooting without requiring customer tool development or locking yourself into a single-vendor proprietary architecture.
Understanding Hadoop’s Redundancy Options
Two switches at the top of each cabinet is a common enterprise recommendation — it ensures that any switch failure doesn’t bring any server down. In a traditional enterprise data center it is a common recommendation. However, in a Hadoop cluster customers have a choice — something every other vendor will not usually recommend: go with a single ToR switch for all cabinets except for the main cabinet that keeps the NameNode and JobTracker servers.
If the NameNode and/or JobTracker fail, the job stops and the cluster fails; these two servers need to be well-protected. However, once you exceed 10 cabinets, any single switch failure will reduce processing capacity by less than 10% and a declining percentage as the cluster scales out. The decision to use network redundancy at the leaf/access-layer becomes an operational decision around network upgrade process more than it becomes about data integrity and data availability as we increasingly trust the file system and application tiers to handle this responsibility.
Data Integrity And Optimization
Because Hadoop is network-aware and the organization of the data structures is based, in part, on the network topology, ensuring that we have an accurate mapping of network topology to servers is of paramount importance. As an example, with Arista EOS, clients can load extensions that let them automatically update the Hadoop Rack Awareness configuration.
This ensures several important things:
- Data is distributed properly across servers so no single point of failure exists. Misconfiguration, or a lack of configuration, could inadvertently enable the NameNode to “distribute” the data to three separate storage nodes that are all connected to the same switch. A switch failure then causes data loss and the data mining job stops, or worse, has invalid results.
- As the Hadoop cluster scales, no human has to maintain the Rack Awareness section; it is automatically updated.
- As nodes age and are replaced or upgraded, the topology self-constructs and data is automatically distributed properly.
- Performance is improved and deterministic because no data is ever more than one network “hop” (single MAC/IP lookup, no proprietary fabric semantics or tunneling games) from the computation that depends on that data. Jobs get distributed to the right place.

Performance
Hadoop performs best with a wire-speed Rack switch. This helps with data ingestion, which is the largest bulk data move the network has to absorb because of the Hadoop Rack Awareness architecture, but more importantly during all operational runtime it eliminates worry and simplifies troubleshooting. If the switch is wire-speed, you only have to worry about the uplinks being congested, not the switch fabric itself causing drops (and simplified troubleshooting). The amount of network capacity between the leaf and spine can be decreased below 1:1 because of the Rack Awareness. This enables us to build larger networks for less cost.
A network designed for Hadoop applications, rather than standard enterprise applications, could make a significant difference in the performance of the cluster.
Ready to learn more about using Hadoop within your business? Contact us and see how Datavision can help you embrace “Big Data” within your organization.


Latest Blog Posts
- SD-WAN & SASE: Secure your network and your information at the Edge
- Protecting Your Information and Your Organization with SD-WAN and SASE
- Datavision uCPE/SD-WAN Reference Solution at MEF18 (and Beyond!)
- The Advent of NFV and Best Practices for Deployment
- ONAP’s Great Potential: What It Means for Service Providers, Vendors & Enterprises